2 answers
- 10-1
Still working on this. We apparently have a database of some sort with at least one use case where it is used internally for these cross references. It has the ability to export the map as a JSON file on a regular interval. I'm investigating if other access methods are available, like secure HTTP endpoint etc. In the mean time, what can Exalate support?
- Francis Martens (Exalate)
Hi,
Our standard support does not include configuration work. We do have a large community of Exalate Partners that can assist here. If you would rather benefit for some solution assistance, check out the Premier Support option, which includes this type of engagement (and much more)
- Francis Martens (Exalate)
If above is not the answer what you are looking for, but rather a technical answer ...
The node can be connected to an external git repo where this json file can reside.
It provides a controlled way to include the json into your incoming/outgoing scripts.
(This is part of the premier support option)
Add your comment... - 10-1
Hi,
There are different ways to implement these, it all depends where the mapping can be stored.
One of the approaches is to use a webservice which contains the mapping, or even an online database ...
Can you detail out where this table can reside?Support for multiple repositories
In version 5.4.0, we enhanced Exalate for Github to support multiple repositories per connection.
Instead of creating hundreds of connections for hundreds of repositories you can work with a single connection- issue.repository contains the name of the repo the issue is coming from
This can be used at the receiving side to select the target project - Triggers are now 'organisation' wide (meaning including all repositories the exalate proxy user can access), and can be refined if necessary using the repo: filter
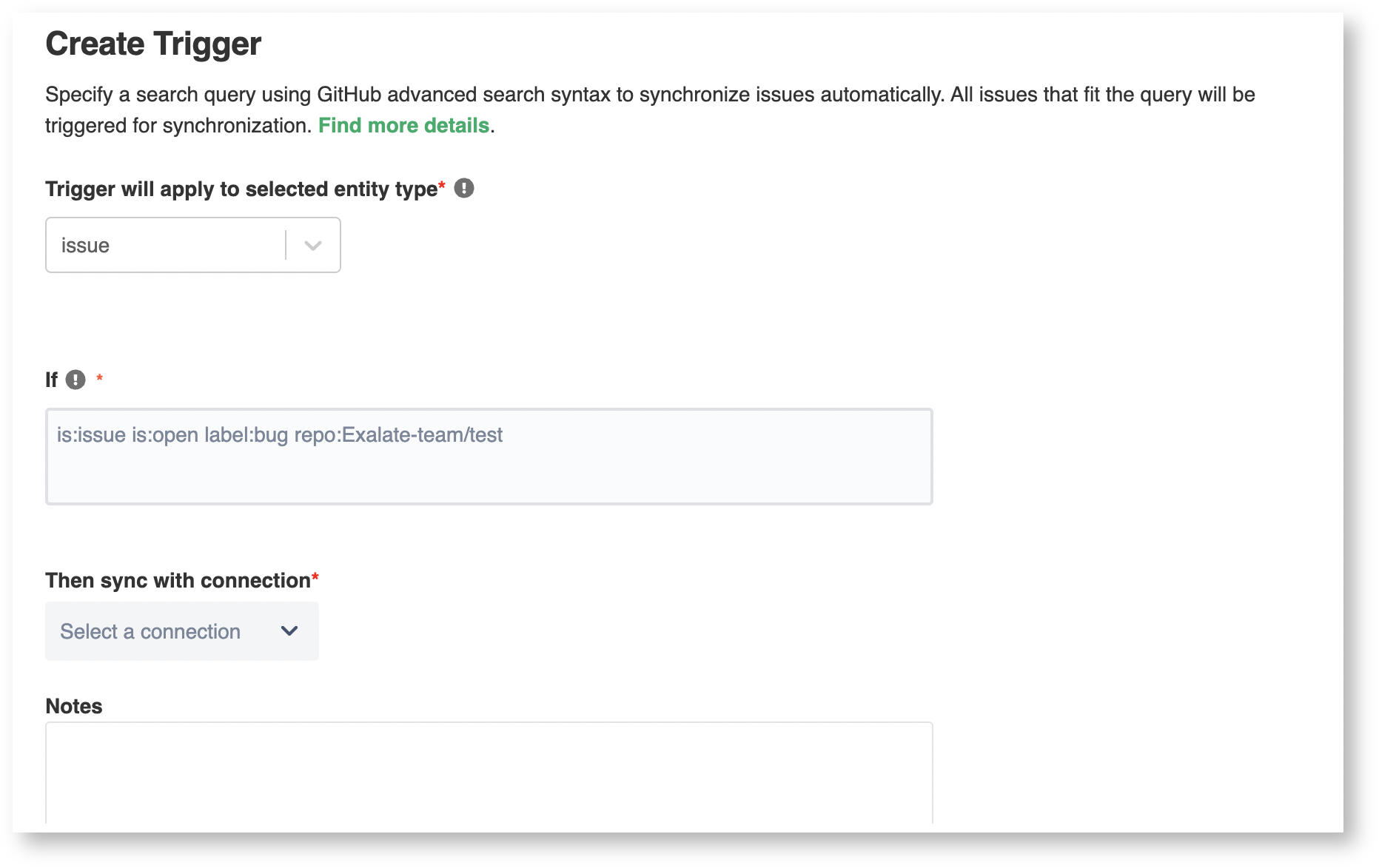
- Petr Klapka
I've found (hopefully) the person in our org who can answer where our lookup table can be found and if it can be accessed via a web service. I'm waiting on a reply from them. Meanwhile, are there certain JSON formats or databases and schemas that Exalate supports for this?
Also, I'm confused by this new relationship and scope of connections, triggers and repos.
My understanding was that a connection was a relationship between exactly one GH repo and exactly one Jira instance. Issues could be syncd to multiple Jira projects via script logic, and there could be multiple triggers per connection. Since triggers are associated to exactly one connection, and a connection is associated to exactly one repo, triggers logically function on just one repo.
Ex: Here is my connection. It applies to a specific repo:
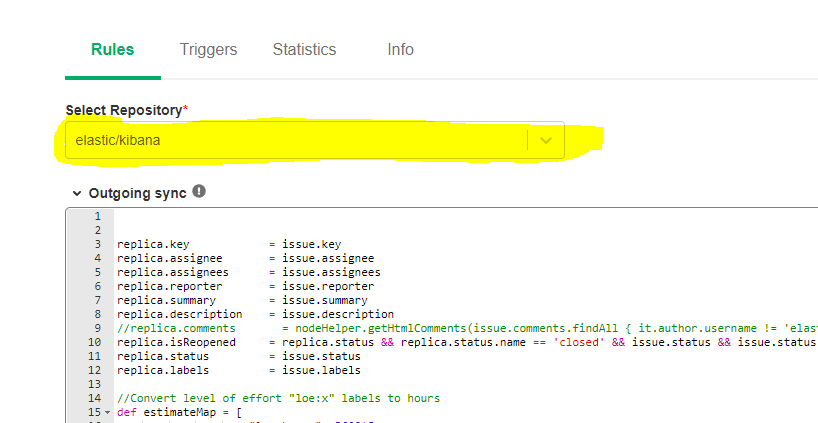
I see no way to make the scripts in the connection apply to more than the the one repo at the top of the UI.
Here is my trigger. It applies to a specific connection:
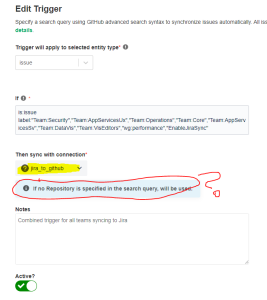
If the connection can only work with one repo, what is the point of being able to specify multiple repos (per your example) in the trigger query?
- Francis Martens (Exalate)
That is the point
> If the connection can only work with one repo, what is the point of being able to specify multiple repos (per your example) in the trigger query?
With the latest version - you can have a connection linked with multiple repo's
So with one connection you can describe the integration between M repo's and N Jira projects - Petr Klapka
Okay, understood that is how it is supposed to work, but the connection still only allows you to select one repo in the UX:

If I create a connection and choose 1 repo (I have no other choice), then I create a trigger that includes multiple repos, and assign the connection to that trigger... what will happen? Will the combination of trigger/connection work on the ONE repo selected in the connection, or on the multiple repos specified in the trigger? That is maybe a better way of expressing the confusion I'm having.
- Francis Martens (Exalate)
First - the reason why you have to indicate a repo is because of historic and backward compatibility
If you would create a new connection, no such setting is there
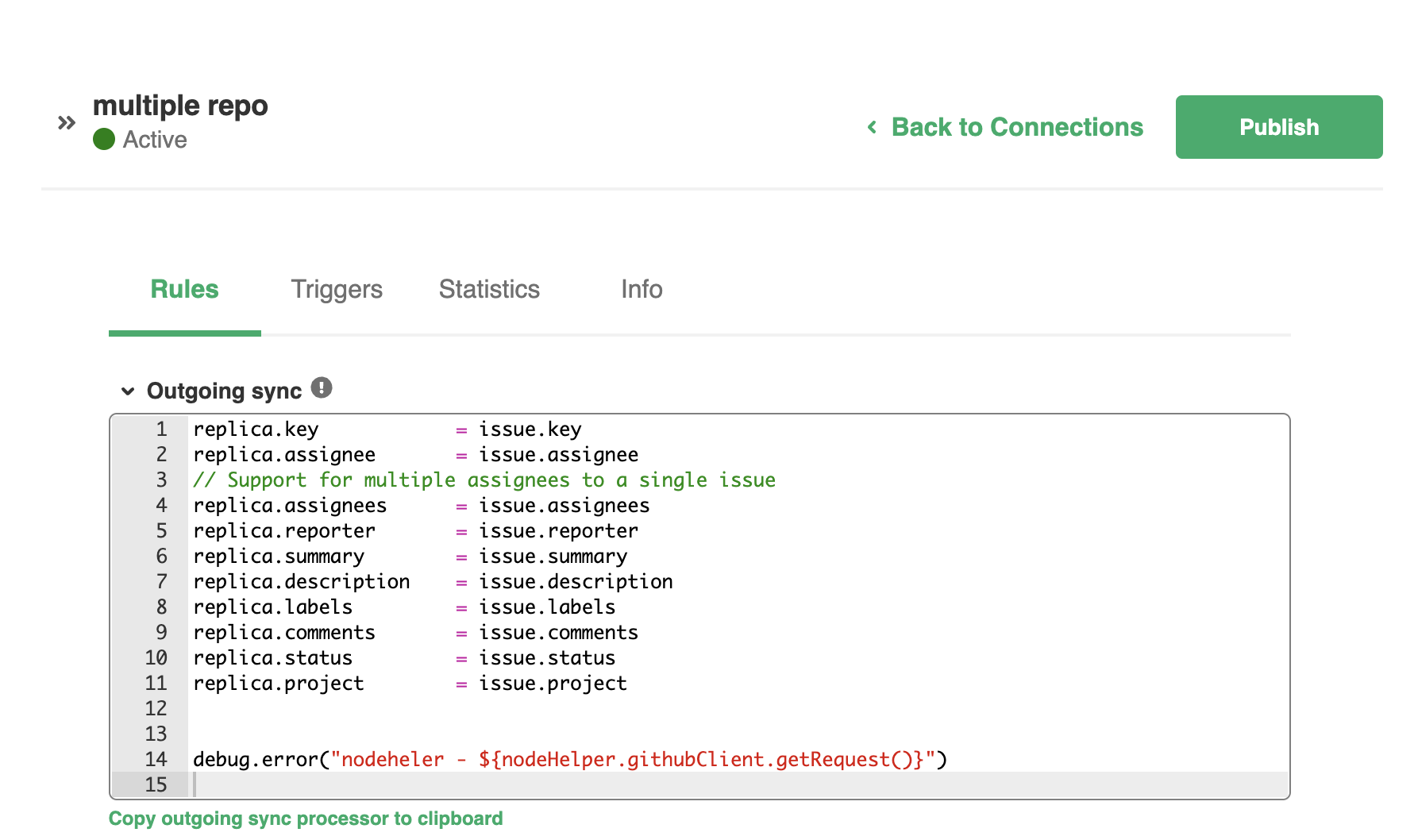
Note however that in the create connection dialog you will find the mandatory dropdown box
This value is used to compose the incoming sync processor - which can be adapted in the next step.The reason why this is in the product, is because if you don't specify a target repo, the first sync an evaluator will try will fail ...
By selecting a repo here
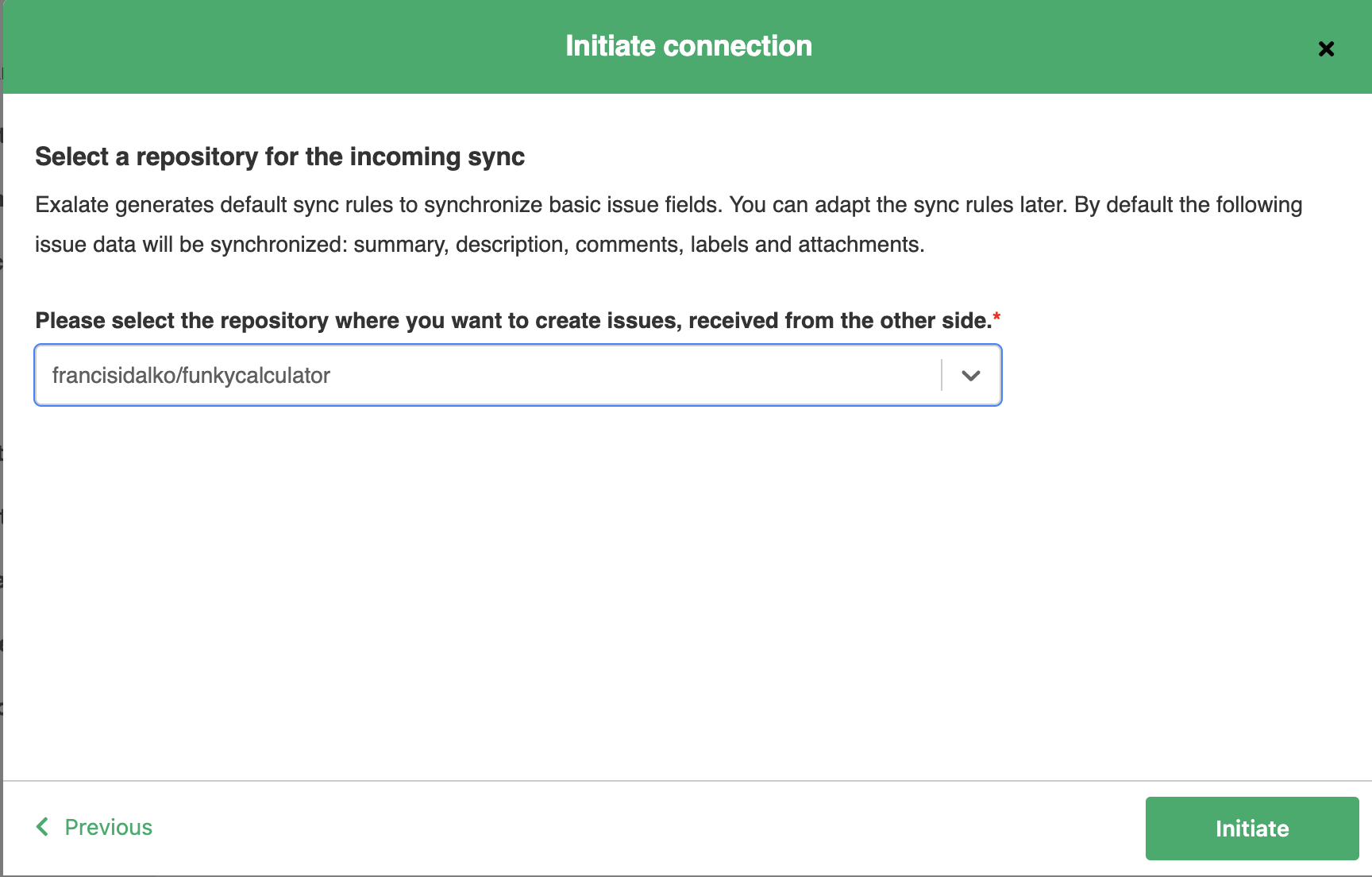
You will get
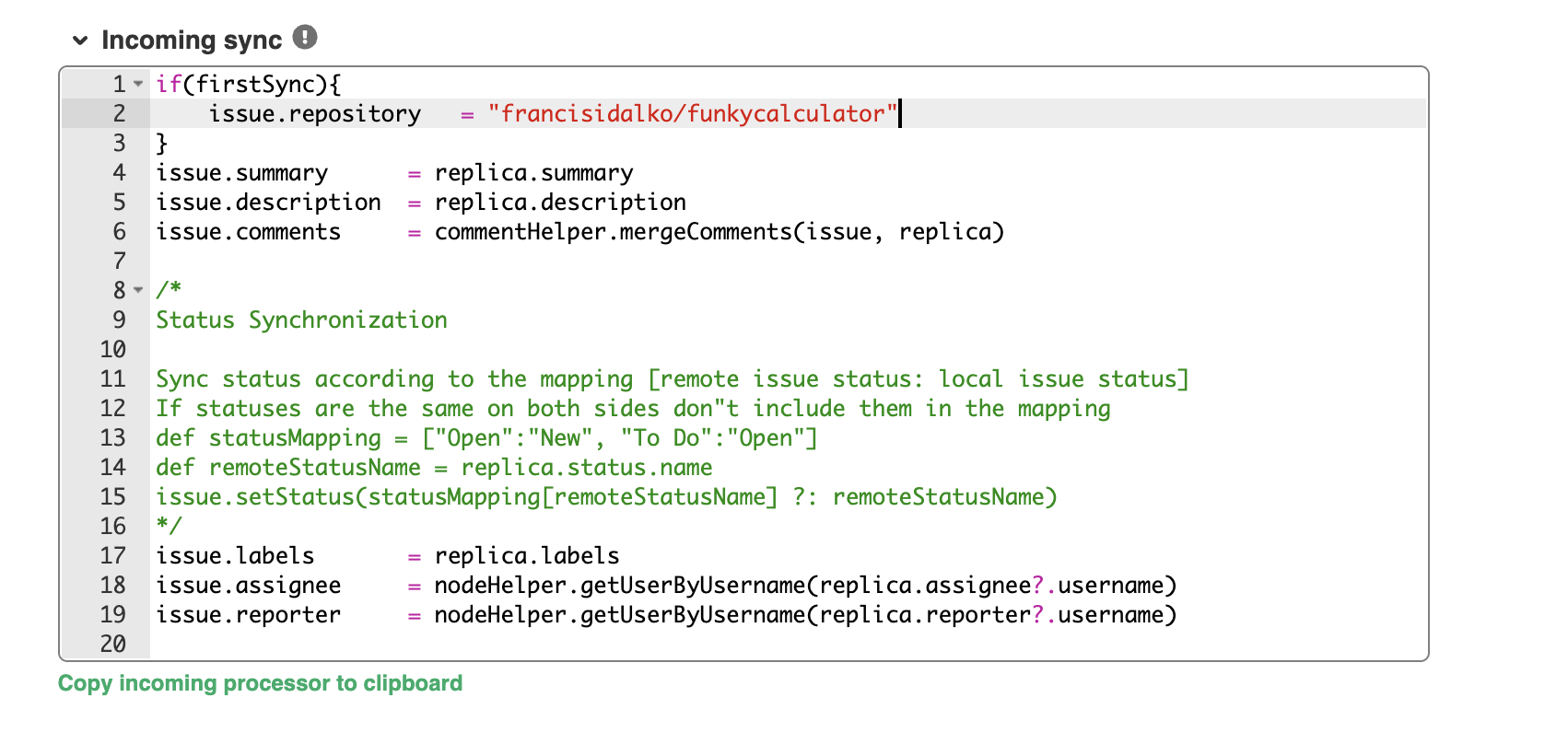
- Petr Klapka
This makes sense now, thank you. Apologies for the segway.
Add your comment... - issue.repository contains the name of the repo the issue is coming from
Our GitHub usernames and Jira usernames do not match. This post shows how to create a lookup table and handle this situation. It will work fine for a small number of users and connections.
We are about to onboard several hundred users and will need to have scripts for syncing dozens of GH repositories to dozens of Jira projects. Is there a way to use a single user lookup table? Is there a way for the sync scripts to access such an external table in some way so the lookup table can be maintained in one place and wouldn’t need to be duplicated in each scripts for each connection?